
Text to Video Generation
Can artificial intelligence generate new video content from text descriptions?
Published July 2017
This project aims to build a deep learning pipeline that takes text descriptions and generates unique video depictions of the content described.
The crux of the project lies with the Generative Adversarial Network, a deep learning algorithm that pins two neural networks against each other in order to produce media that is unique and realistic.
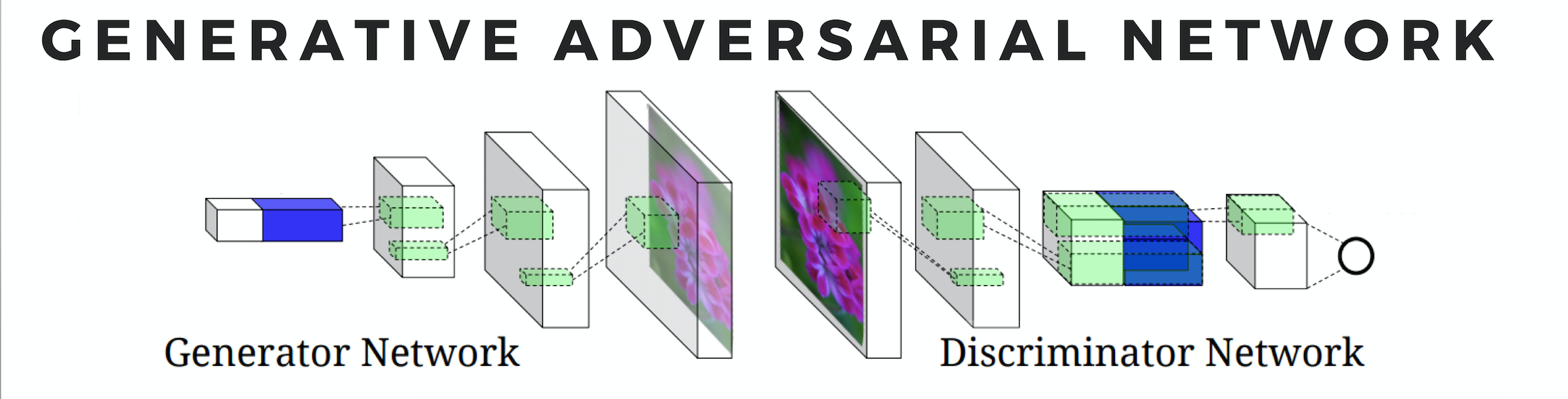
Credit: Scott Reed
This model consists of a generative network and a discriminative network. While the generator produces new content, the discriminator tries to identify the generator's work from a pool of real and fake (aka generated) media. The discriminator produces a "'real" or "fake" output label for each piece of content made by the generator. The "fake" labels are then treated as errors in the generator's back-propagation.
This adversarial design has been shown to greatly outperform many generative models used in the field. As the discriminator gets better at distinguishing the computer-generated from the human-generated, the generator improves in producing more realistic media.
Perhaps the two largest downsides of using Generative Adversarial Networks is that they are both hard to train and hard to evaluate. We'll discuss some techniques used to mitigate these challenges in this project.
Dataset
For training, I used The Max-Planck Institute for Informatics (MPII) Movie Description dataset. The dataset includes short movies snippets, as well as textual depictions of what is featured in each video. The text comes from a audio description service aimed at helping visually impaired people better follow a movie. More information on the dataset can be found in this published paper.
I used video-description pairs from 9 romantic comedies with the aim of training my algorithm to generate videos of humans in action.

Credit: CVPR Paper
ML Pipeline
To recap, the goal of this project is to input text descriptions into a series of ML models that produce a video of said description as output.
The overall pipeline looks something like this:
- Vectorize and embed the text into latent space
- Use GANs to expand the text embeddings into a series of images
- Convert the series into a GIF
Embedding Text Descriptions

Find Keras code for the Variational Autoencoder used in the project here.
I first vectorized the text descriptions using Facebook's fastText word2vec. This was done by concatenating the word vectors in each sentence. The vast majority of the descriptions in the dataset are 25 words or less, so I limited the concatenated vector length to 7500 dimensions (300 dimensional word vectors * 25 words). Descriptions that were shorter than 25 words had their vectors extended to the 7500 dimensional size with a padding of zeros.
I chose to concatenate the word vectors instead of average them in an attempt to keep some of the semantic ordering in tact. Variational Autoencoders have been shown to embed entire sentences into latent representations quite well, sometimes outperforming LSTMs (study linked here). With this in mind, I ran the description vectors through a VAE in order to reduce their dimensionality and get more meaningful embeddings.

Find Keras code for the Multimodal Embedding Network used in the project here.
The Variational Autoencoder works to cluster embeddings with similar semantic patterns. However, visualizing that text down the road requires a more nuanced embedding framework.
Visualizations of thought tend to bring out a lot of the implicit context present in the explicit text. Descriptions of birds tend to visually elicit tree branches and bird houses. Descriptions of kicking a ball can lead us to image soccer, green grass, and shorts. So how can a model learn to pick up on the implicit meaning of a language? And is there any way to help it along the way?
Joint Multimodal Embedding Networks have been shown to provide promising results in this direction. They try to cluster lower dimensional representations of different media with similar subject-matter. I used a Siamese Network with text and image encoders to develop this type of design. The model decreases the euclidian distance between embeddings of images and their text descriptions and increases the euclidian distance between embeddings of images and unrelated text.
The text encoder in the trained Siamese Network was then used to create the final latent embeddings for each video description. This encoder added several fully-connected layers on top of frozen layers from the pre-trained VAE encoder above.
Stacking GANS
Once the descriptions are embedded into a lower dimensional space, they can be used as inputs in a General Adversarial Network.
The GANs used in the project were adapted from these two papers:
Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
Generating Videos with Scene Dynamics
The first GAN was trained to convert text descriptions into image depictions of the text's content. The second GAN was trained to take those generated images as input and extend them into a series of 32 frames.

Find Tensorflow code for the text-to-image GAN used in the project here.
I recreated the study going from "text to photo-realistic image" with the code above. The dataset provided allowed the network to learn how to generate realistic bird images from detailed descriptions of birds.
Here is a sample of my results. The text descriptions on the left were the input that produced the bird images directly to the right of them. As you can see, the images coincide with the descriptions quite well. The generated birds are also quite diverse.

The study referenced stacked a second GAN on top of the first to continue upsampling and thereby converting the low resolution images into high-res outputs. Training individual epochs of this model took an extremely long time, even on high-tier AWS instances, so I decided to skip this phase when training on my own data. In the future, I look forward to fully implementing this step of the process with a slightly altered and hopefully quicker high-res producing GAN.
Here is an example of the output of the second GAN. The images below are from the study itself.

Credit: Han Zhang Github
Video GAN
The next model I ran took the images generated above as input and produced a horizontally long graphic that includes 32 sequential frames, one of which will ideally be the input image itself.

Find Torch code for the image-to-video GAN used in the project here.
This model is able to generate videos on distinct subject matter quite well. The branching convolutional layers encourage the model to split the input image into it's foreground and background components. Typically, the majority of the movement in a video occurs in the foreground. Therefore, the model replicates the static background in each frame while combining the moving foreground into the frames using a mask.
The output image is then sliced into its competent frames and made into a GIF.
Here are examples of train and beach videos produced by the study itself.












Results
Deciding when to stop training a GAN can be tricky work. You can check the content produced by the generator at different stages in the training process, but this is only helpful once relatively realistic content begins to show. What do you do beforehand? Monitoring the generator and discriminator's loss can be an additional method of evaluating the GAN.
As mentioned above, a GAN's discriminator will typically begin with very low accuracy and therefore high loss. Because the GAN's generator also starts out quite horribly, the discriminator will very quickly be able to distinguish generated images from real-life ones. As the discriminator's error drops, the generator slowly begins to find ways to trick the discriminator and reduce its loss as well. Typically the generator will improve one aspect of its images at a time. This allows the discriminator to once again pick up on patterns in the generated images, label them as fake, and once again begin increasing the generator's loss.
One typically hopes to stop training the GAN when the generator's and discriminator's losses begin to close in on each other and stabilize. This will ideally happen at the second local minima of the generator's loss plot.
Below is a screenshot from my loss plot midway through my training process.
As you can see the generator's loss drops initially and then begins to curve upward as the discriminator picks up on its antics. Following the 6000th training step and not visualized here, the loss began to drop again.

Here is a sample of images produced by the first generator. As you can see they look like various frames from snippets of a romantic comedy.
You can also see that the generator repeats images at different points. Those generated frames must have fooled the discriminator better than the rest, risking stagnation in the training process.

Here is a sample of videos produced by the second generator. The first picks up on a couple dancing or hugging, while the second seems to form a boxy humanoid form interestingly not found in the movies themselves.


While individual photos and videos from the GANs created interesting content reminiscent of a romantic comedy, the overall meaning of text descriptions broke down as they went through the process. Here are three columns showing the initial text description, followed by the image output of the first generator, and the video output of the second generator.
While the image output may have picked up on some of the meaning in the text, the videos themselves entirely lose it. They do make for some fun psychedelic GIFs though.




Limitations
While the ML pipeline was complete, the results ultimately need some improving on. The causes of the breakdown in meaning from text description to video may not be fully remediable, but I believe that another run of the models with a more refined dataset can produce much, much better results.
The dataset used, video clips from nine romantic comedies, was unfortunately too varied in subject matter and too low resolution from the start to provide meaningful results.
While the consequences of this became apparent during the project, it was too late to turn back. Filtering the dataset for higher quality videos on less varied subject matter will ultimately require significantly more image editing work and perhaps the design of a classification model to aid in the process.
Another large limitation of this project design was the disconnect between the initial text vector and the final video-GAN. While I did not have time to further modify the second GAN's framework, I see several potential ways to improve it - discussed below.
Future Runs
I believe this pipeline will run quite well on higher quality videos that stick to a specific subject matter. I'm currently looking for available datasets and scrape-able material that will be good for this use.
Additionally, I believe that tokenizing for the action words in the text descriptions and putting an additional focus on these word vectors during the embedding stage will prevent the contextual breakdown that this project faced.
Changing video generation model to be more like the image generation one will also improve the results. The image generation model takes into account whether the image is a match with its text description when deriving the loss. The video generation needs a similar data and loss function design.